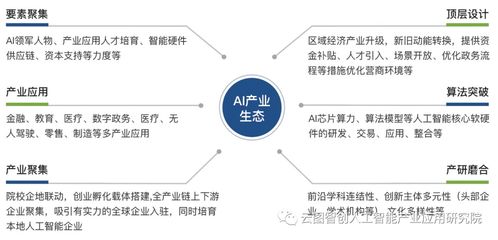
在人工智能技術飛速發展的浪潮中,社交媒體巨頭Facebook再次邁出重要一步。該公司正式發布了其最新的人工智能產品——DeepText。這款引擎的核心宣稱是能夠以近似人類的智商水平,實時識別和理解用戶在聊天、評論等場景中的文本內容,這標志著自然語言處理技術在實用化道路上取得了關鍵性突破。
技術核心:超越關鍵詞的深度理解
DeepText并非傳統的關鍵詞匹配工具。它基于深度學習技術,特別是遞歸神經網絡和卷積神經網絡,能夠從海量的非結構化文本數據中學習語言的細微差別。這意味著系統不僅能識別單個詞匯,更能理解上下文語境、俚語、雙關語、多義詞以及不同語言之間的混合使用(例如中英文夾雜的聊天)。例如,當用戶說“蘋果發布會真棒”時,DeepText能準確判斷這里的“蘋果”指的是科技公司而非水果,并根據上下文關聯相關的科技新聞或產品。這種理解能力使其“智商”更接近人類對語言的直覺處理。
應用場景:從提升體驗到商業賦能
DeepText的發布,預示著Facebook平臺及其家族應用將迎來一系列智能化升級:
- 精準的廣告推送與內容推薦:通過深度理解用戶在Messenger或評論中的對話內容,系統可以更準確地推斷用戶的實時興趣與需求,從而推送高度相關的廣告或新聞資訊,提升商業轉化率與用戶體驗。
- 增強社交互動與安全:它能自動識別并過濾垃圾信息、騷擾內容或潛在的欺詐行為,例如在買賣群組中識別虛假商品描述。它可以幫助連接有共同興趣的用戶,或為用戶的提問自動推薦相關群組或頁面。
- 無縫的多語言交流支持:在全球化社交中,DeepText能實時翻譯或理解多種語言混合的對話,打破語言壁壘,讓交流更加順暢。
- 作為開發者的強大工具:Facebook將DeepText作為技術框架開放給開發者,第三方應用可以集成其文本理解能力,用于構建更智能的聊天機器人、客服系統或內容審核工具,從而催生新一代的AI驅動應用。
技術開發的挑戰與未來展望
盡管DeepText代表了當前的前沿水平,但其開發仍面臨諸多挑戰。語言的復雜性和動態變化(如網絡新詞的不斷涌現)要求模型必須持續學習。如何確保AI的理解不帶有偏見、保護用戶隱私和數據安全,是Facebook必須解決的倫理與工程難題。
從技術開發角度看,DeepText的成功依賴于三大支柱:龐大的數據量(Facebook每日處理的數十億次互動)、強大的計算基礎設施以及頂尖的AI研究團隊。它的發布不僅鞏固了Facebook在AI領域的戰略布局,也為整個行業樹立了文本理解的新標桿。
隨著技術的迭代,我們可以期待DeepText從“理解”向“生成”和“對話”演進,最終實現與人類進行自然、流暢、富有情感的交互。這不僅是AI技術的進步,更是我們數字化社交生活的一次深刻變革。Facebook通過DeepText再次證明,人工智能正在從感知智能向認知智能深度邁進,而理解人類的語言,是通往這一目標的核心鑰匙。